Ask a question, get an answer, and gain valuable insights across the precision medicine data ecosystem.
Powered by the first ensemble of Precision Medicine Large Language Models (LLMs)
Supercharges the day-to-day work of translational researchers, data scientists, and informatics teams.
Join Bill Hall as he chats with QuartzBio’s Virtual Assistant, conversationally extracting insights in seconds with questions such as:
“Which mutations have highest prevalence at baseline?”
“Which subjects are in the 70th percentile of JAK2 expression at baseline and have stored, consented, baseline samples?”
“What is the correlation of JAK2 and STAT1 expression at baseline across samples?”
You’ll discover QuartzBio’s approach, which employs smart, automated integration of biomarker, sample, and clinical data to create a unified data ecosystem – now amplified with the power of conversational interactions to enable more consumable insights, regardless of your data expertise.
Who should attend:
Translational Scientists Data Science and Bioinformatics Teams R&D Information Technology (IT)
https://www.quartz.bio/wp-content/uploads/2024/07/Linkedin_Webinar-SEPT2024_Empowering-PM-with-Conversational-AI_A.jpg10801080Chandreyee.Dashttps://www.quartz.bio/wp-content/uploads/2022/03/logo.svgChandreyee.Das2024-07-26 15:14:102024-07-26 15:14:10Webinar: Empowering Precision Medicine with Conversational AI — A New Era of Biomarker Intelligence
It was late in the afternoon, a windy day in Boston, as we listened to precision medicine development leaders within pharma and biotech spaces get excited about applying AI to their day-to-day work.
“We’ve gone from optimism to real opportunity here,” said one precision oncology team lead, eliciting nods across the room.
The explosion of generative AI and, specifically, large language models (LLMs), has created renewed energy, focus and promise around the hype of AI impacting the R&D lifecycle. Generative AI is revolutionizing precision medicine clinical trial planning, execution, and operations. Organizations are increasingly recognizing its potential, rallying behind AI initiatives. The race is on – the race to leverage AI as a force multiplier, knowledge amplifier and value generator, ultimately accelerating time-to-insight.
How can generative AI deliver on these promises?
Applications of generative AI and LLMs in precision medicine
AI-enabled technologies are empowering precision medicine development teams to make better decisions, faster, thanks to AI augmentation of human efforts in data processing, pattern recognition, insight generation, broadening of use cases, and performing complex queries.
As a result of these capabilities, the list of use cases for generative AI in drug development grows longer each day: drug target identification, target prioritization, patient selection, trial design, protocol generation, site management, trial monitoring, biomarker data analysis, regulatory submissions, and more.
Example use case 1: Extracting insights from previous precision medicine clinical trials to inform subsequent studies. AI and machine learning algorithms can help researchers organize and interrogate billions of existing clinical trial data points, including clinical annotations of collected samples, information from scientific literature, and exploratory biomarker data, before a new clinical trial begins.
The insights from these data sets can help identify drug targets, define the patient populations most/least likely to respond, and even identify relevant, stored clinical samples from closed studies that have been consented for future biological research.
Example use case 2: Optimizing operational efficiency of precision medicine clinical trials. Biomarker-informed clinical programs depend on the right samples and their associated data / metadata trails arriving at the right place, at the right time.
Augmenting the hard work of human clinical operations, biomarker and sample operations teams, AI-enabled technologies can monitor sample collection, informed consent and compliance, data generation, and data quality, surfacing inconsistencies in time for intervention.
Human power, optimally utilized via efficient workflows and streamlined processes, remains a key determinant of the success of a clinical program. Our goal is to establish a framework in which AI-enabled technologies amplify the talent and knowledge of human teams.
QuartzBio’s approach: amplifying talent and knowledge with generative AI and LLMs
As domain-specific LLMs proliferate, precision medicine development organizations are discovering that these technologies have the most impact when they enable not just one team, but key stakeholders across the entire precision medicine R&D lifecycle – human-centricity and AI as an amplifier is a key focus of many organizations. In the words of Samer Ansari, Takeda Oncology’s Head of Data, digital transformation is “really about elevating the human experience.”
Organizations are moving away from point solutions, each of which address a narrow use case, and towards platform-based solutions with two key characteristics:
Platform-based solutions address broad use cases, such as the entire precision medicine development lifecycle.
They can be easily deployed in the space of a more broadly connected, interoperable data and technology ecosystem.
The Precision Medicine Ecosystem and its interaction with QuartzBio’s Biomarker Intelligence Platform, creating a framework for amplifying knowledge and talent across all stakeholders and teams across the enterprise. The enterprise can consist of one or many clinical programs at all stages of development.
The industry’s experience with traditional technology applications supports the need for a unifying AI-enabling framework. The average organization uses 130 different software applications, and the average worker must toggle between applications over 1,200 times a day. The result is that information and insights stay in siloes, and teams exert enormous effort just to connect data and technology.
Imagine an AI-enabled precision medicine intelligence platform, optimized for augmenting the daily work of biomarker operations teams, translational scientists, sample operations teams, data scientists, R&D IT teams, and executive-level stakeholders.
Such a tailored platform would multiply the force of each team member by empowering them with role-specific insights, based on high-quality, interconnected data, while also making it as easy as possible for teams to work together. This is the vision behind QuartzBio’s next-generation approach to generative AI for precision medicine intelligence.
Three pillars of precision medicine intelligence: conversational, prescriptive, and navigational AI
There are three core concepts that form the foundation of our approach to precision medicine intelligence: conversational, prescriptive and navigational AI.
Conversational AI enables users to conversationally interact with the precision medicine data ecosystem using natural language, for both data management and insight generation. In response, conversational AI provides easily digestible outputs and insights without requiring users to navigate the complex underlying data structures.
Prescriptive AI proactively serves up information around data anomalies and operational trends, then recommends potential actions to take based on this information.
Navigational AI drives a re-envisioned user interface for precision medicine intelligence, guiding users to the specific data, insights, and modules of an application fit for their immediate needs.
Considerations for building a generative AI framework for precision medicine
As we build a generative AI framework out of an ensemble of conversational, prescriptive, and navigational LLMs, there are four main considerations to ensure that the resulting technology remains practical and usable:
System and ecosystem interoperability via a scalable, modular approach
Task and domain specificity, including specificity for user personas
Compliance, including data privacy and security, without hampering innovation
Balancing accuracy, speed, and cost efficiency
In this series of posts, we will explore the details of each of these considerations.
And if you’re interested in joining one of our in-person Biomarker Intelligence Summits for R&D organizations to share challenges and opportunities facing data-rich clinical programs, please get in touch.
https://www.quartz.bio/wp-content/uploads/2024/07/QB_AI_LLM-Article_Evolving-Impact_1200x1200_v1.jpg12001200Chandreyee.Dashttps://www.quartz.bio/wp-content/uploads/2022/03/logo.svgChandreyee.Das2024-07-09 12:17:202024-07-22 13:33:17From Optimism to Opportunity: Evolving Impacts of AI on Precision Medicine
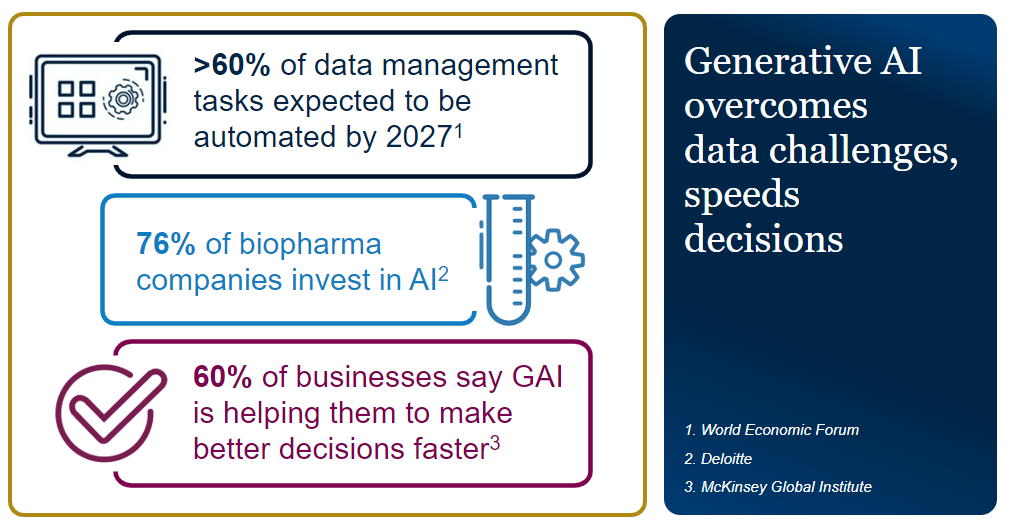
Last week, biomarker intelligence leaders from Boston-area R&D organizations got a firsthand look at the powerful predictive and prescriptive intelligence that will soon infuse QuartzBio’s AI Biomarker Intelligence Platform, after sharing common challenges facing data-rich precision medicine clinical programs.
Even though our guests represented organizations that varied in size, number of clinical trials, and therapeutic area, they all shared the challenges of disconnected technology and data ecosystems. Over three million data points are generated per clinical trial and over 70% of that data comes from labs. Sponsor organizations are realizing that they are missing opportunities to advance precision medicine if they do not address their data and technology challenges.
Guest speaker and AI expert, Srivatsan Nagaraja, described the potential of generative AI (GAI) and large language models to overcome these challenges and speed decision-making; not surprisingly, 76% of biopharma companies are investing in AI.
Srivatsan left the audience with two takeaways:
“Generative AI is not going away – and the journey is as important as the destination.”
The journey, in this context, refers to
How the GAI model is trained and prompted – ideally, by subject matter experts and domain-specific knowledge, iteratively improving the value derived from AI
The quality, structure, and format of the underlying data
The QuartzBio team gave a quick demo of their AI-powered Biomarker Intelligence Platform, showing guests how they could get a 360° look around their sample ecosystem in seconds.
We wrapped up the Biomarker Intelligence Summit with a networking happy hour and hands-on exploration stations. Guests interacted with QuartzBio’s conversational AI Virtual Assistant, experiencing how it could help derive valuable insights quickly and easily.
Have a burning question for our team and/or the QuartzBio AI Virtual Assistant?
https://www.quartz.bio/wp-content/uploads/2024/03/QB_Linkedin_BI-Summit_Boston-Recap_01232024_v1-1.jpg12001800Chandreyee.Dashttps://www.quartz.bio/wp-content/uploads/2022/03/logo.svgChandreyee.Das2024-03-25 10:32:162024-03-26 16:19:19Key Takeaways: Biomarker Intelligence Summit, March 2024
February 11-14, 2024 | Orlando, FL, USA
Curious if an AI-enabled solution is right for your clinical sample management? At this year’s SCOPE (Summit for Clinical Operations Executives) conference we’ll be presenting:
“Tell me what I don’t know: AI-enhanced decisions in biomarker-informed trials” 12:20 PM, Monday February 12, Operationalizing Biomarker & Precision Medicine Trials track
where you’ll learn about deploying generative AI in drug development.
We’ll demonstrate how conversational AI empowers users to extract insights from sample and biomarker information. Additionally, we’ll discuss how predictive features of GAI may enable novel insights by proactively surfacing information instead of passively waiting for input.
https://www.quartz.bio/wp-content/uploads/2024/01/QuartzBio-at-SCOPE-2024.jpg7991200Chandreyee.Dashttps://www.quartz.bio/wp-content/uploads/2022/03/logo.svgChandreyee.Das2024-01-18 13:04:202024-02-09 12:04:15Join QuartzBio at SCOPE 2024 | Booth #300
QuartzBio’s team has deep experience in technology-enabled solutions for the life science industry. In this blog series, we invited you to get to know a member of the QuartzBio team.
This month, we are delighted to talk with Katie Berola, Director of virtual Sample Inventory Management. After learning about Katie here, please feel free to connect with her on LinkedIn.
In your own words, what do you do? I build tools that take a process that is necessary and time-consuming and make it better and faster.
Subjects in clinical trials are volunteers. Some patients consent without knowing if the treatment will help them. Others consent knowing the treatment will likely not help them, but they volunteer anyway. At the end of the trial, the samples and the data are all that is left. Building tools to take all that knowledge gained, even in failure, and make it useful for the future is a part of respecting the patients’ sacrifice. For some patients, that sacrifice can be precious hours in the last weeks and months of their lives.
I am passionate about data quality, making research better, and helping patients have better outcomes.
What is your fondest memory of working at QuartzBio? My fondest memory was when I came to this company and realized they encourage innovation and creativity.
The priority to deliver our clients’ expectations is high, but equally high is the expectation to continuously improve and develop our tools. It is inspirational to know that if improvement is possible, I will be encouraged to pursue that improvement even if a different method already exists.
Complete this sentence: QuartzBio is _________ because _________. QuartzBio is cutting-edge because we do not stop creating solutions. The team here faces new challenges frequently and strives to solve them.
Complete this sentence: QuartzBio customers are _________ because _________. QuartzBio customers are an opportunity to enhance or expand our tools because there are always new challenges and different needs. Some of the best product features we have developed originated from QuartzBio customers, and those features have then been used to benefit all customers.
What piece of art – book, movie, music, artwork, etc. – inspired you the most and why? It was very hard to choose as I am inspired by many things!
My favorite example is the Lord of the Rings trilogy. Taking what is one of the best fantasy stories ever written and blending artistry and technology to bring it to life is truly amazing. It’s a beautiful combination of human creativity and scientific advancement.
What’s the best piece of advice you have ever been given? There are ten solutions to every problem. The first solution, while functional, may not be elegant. It is our responsibility to keep working to find the other nine solutions to achieve both functionality and elegance.
Dr. Yanak is known in the Biospecimen and Biomarker Operations field for her transformative work in translating scientific strategy into clinical operations, via technology and innovation, across both biopharma and central labs. Her efforts have succeeded in drawing attention to biospecimens, which are central to diagnosis and treatment.
However, as she points out in this article, transparency in biospecimen chain of custody is frequently lacking, with responsibilities split among multiple organizations, leading to unclear processes, extended timelines, and inefficiencies.
Dr. Yanak’s article highlighted both challenges of current processes and specific ways to improve biospecimen management:
Challenges Present in Traditional Biospecimen Operations:
Roles and responsibilities among various teams, both internal and external, are often unclear.
Lack of transparency in biospecimen chain of custody contributes to extended clinical trial timelines.
Manual tracking using Excel spreadsheets is common, leading to inefficiencies and potential errors.
Improving Biospecimen Management:
There is a need for Quality Management System (QMS)-level specimen management processes.
https://www.quartz.bio/wp-content/uploads/2023/11/QB_Brenda-Yanak_Spotlight_11282023_V2.jpg12001200Chandreyee.Dashttps://www.quartz.bio/wp-content/uploads/2022/03/logo.svgChandreyee.Das2023-11-29 17:00:212023-11-30 15:20:34Spotlight on Specimens: Innovations in Biospecimen Management May Transform Precision Medicine
Explore patient biomarker profiles across assays and vendors with a single solution
Duration: 30 minutes
Sign up to watch the webinar:
What you’ll learn:
Biomarkers, when used to guide clinical programs, could mean the difference between success and failure.
But exploratory biomarker data can be a headache to manage. Translational and data science teams struggle with disconnected data flows from specialty labs, sponsor data processing pipelines, and clinical data stores.
Join Bill Hall for a webinar demo of the QuartzBio® enterprise Biomarker Data Management solution.
We’ll show you how to
Generate patient profiles to view tumor burden over course of treatment
Explore multi-marker views of patient profiles
Review ancillary data (e.g. images)
Evaluate patient profiles on a cohort level
Cross-reference biomarker measures across file types; e.g., compare ctDNA profiles of interest with clinical efficacy biomarkers such as immunohistochemistry
Who should attend: Translational Research teams, Biomarker Operations teams, Clinical/Biomarker Data Science teams, Clinical Development teams, Bioinformatics and Computational Biology teams, Office of the CIO/CTO, Data Management teams
https://www.quartz.bio/wp-content/uploads/2023/08/20230913-eBDM-Webinar-LP-Image.png12001200Chandreyee.Dashttps://www.quartz.bio/wp-content/uploads/2022/03/logo.svgChandreyee.Das2023-08-11 11:29:582023-09-15 14:25:47Webinar: Unifying Clinical & Biomarker Data
Duration: 30 minutes
Register to Join the Webinar:
Summary:
“Sample tracking and reconciliation are so much easier when all information around sample status, consent, and location are in one place.”
–Director of Biomarker Operations, QuartzBio Client Company N
Watch our webinar to learn how our clients, representing major biopharmas and biotechnology companies, have eliminated tedious data management processes and costly delays with the QuartzBio® virtual Sample Inventory Management SaaS solution.
QuartzBio’s Adam Brown, PhD, demonstrates new capabilities of our technology, enabling teams to:
Track samples across every stage of their lifecycle with dynamic reports comparing actual and expected sample status
Proactively monitor sample stability and consent expiration with automated notifications
Quickly and accurately identify samples to ship for testing using intuitive Sample Ship List generator
Report on portfolio-level metrics and vendor and site performance across all clinical programs, including closed and active studies, to inform future planning
Adam also shows QuartzBio’s reimagined user interface*, which empowers teams to gain insights efficiently without requiring data expertise. Whether you are a current user or learning about the technology for the first time, you will learn new ways to immediately begin streamlining your work.
*Current QuartzBio Users: Questions about when you can expect rollout of the new user interface for your account? Contact us!
https://www.quartz.bio/wp-content/uploads/2023/06/QuartzBio-Digitizing-Biomarker-Operations-webinar-June-2023.png12021200Chandreyee.Dashttps://www.quartz.bio/wp-content/uploads/2022/03/logo.svgChandreyee.Das2023-05-31 12:46:002023-08-07 11:28:45Webinar On Demand: Digitizing Biomarker Operations–Tools to Track & Report Sample, Consent, Vendor, & Site KPIs Across Programs
AI/ML can be a powerful, error-reducing tool for managing clinical sample data as well as biomarker data.
AI/ML-based tools should not replace human judgment, particularly for insight generation, at least until AI/ML-based tools are extensively and rigorously validated (as any piece of critical software would be). Furthermore, regulatory compliance and data privacy are of utmost importance and must be considered when building and using solutions that leverage generative AI frameworks.
However, near-term applications of AI/ML can dramatically improve any tedious process involving a human inspecting data. We list some of these processes in the box below, along with steps we recommend taking to reduce risk in each case.
https://www.quartz.bio/wp-content/uploads/2023/05/AI-ML-processes-in-drug-development-by-QuartzBio-202305.jpg12001200Chandreyee.Dashttps://www.quartz.bio/wp-content/uploads/2022/03/logo.svgChandreyee.Das2023-05-25 15:28:412023-05-30 16:53:18Unleashing Innovative, AI/ML-Based Processes While Reducing Risks for Drug Development
QuartzBio’s suite of end-to-end SaaS solutions provides pharmaceutical and biotech clients with a fully connected data ecosystem linking sample, biomarker, and clinical data to improve collaboration, planning, and R&D productivity.
Frederick, MD – January 24, 2023– Precision for Medicine, the first global, precision medicine clinical research services organization, today announced the strategic acquisition of SolveBio by QuartzBio.
SolveBio’s intelligent technologies and enterprise data management platform has integrated into QuartzBio’s suite of SaaS solutions, providing a single, scalable solution supporting clinical sample inventory management and biomarker data management for the biotech and pharmaceutical sectors.
The combined offerings under QuartzBio provide scientific and operations teams in drug development with an agile, user-friendly data management platform that enables enterprise-level visibility across the lifecycle of their sample and biomarker data. Leveraging this expanded enterprise suite of solutions, scientists in translational research and clinical operations can more easily collaborate across functions, analyze and report on key datasets, and generate insights.
“We are excited to have SolveBio joining forces with QuartzBio,” says Scott Marshall, Ph.D., General Manager of QuartzBio. “As our industry continues to innovate, it is imperative that we continue to advance our portfolio of enterprise solutions to enable scale and connectivity in support of our ultimate goal – delivering therapies to patients. Integrating SolveBio’s technology with QuartzBio’s existing portfolio helps us accomplish that.”
QuartzBio’s fully connected, end-to-end SaaS solutions are engineered to enable seamless monitoring and tracking of clinical sample status, informed consent form (ICF) tracking/codification, and management of biomarker data across the enterprise, resulting in a unified solution for the management and delivery of both samples and their related biomarker data. The platform is used to generate scientific and operational insights, while studies are in progress, after studies are complete, and across multiple clinical programs.
Combining the QuartzBio and SolveBio teams’ expertise and scale, QuartzBio can now better support clients’ strategic goals and day-to-day productivity by helping clinical and translational teams:
Save time with technology that maps data as-is, from any source, using the format provided by the lab, vendor, or other source systems with no changes required—increasing flexibility and speeding deployment.
Gain visibility into sample status with virtual Sample Inventory Management, a single source of truth linking samples and derivatives with clinical data, informed consent, shipping status, and more – across multiple sites, labs, and repositories.
Increase efficiency and reporting accuracywith enterprise-wide Biomarker Data Management, as all sample-related data will be centralized and harmonized in a unified data platform, thus eliminating the need to search for data in multiple storage locations.
Consolidate visibility to stored samples from all studies (active and inactive) with virtual Biorepository, across geographies, biorepositories, and central labs (long-term storage) to facilitate planning for future data generation.
Collaborate and connect by leveraging biomarker-specific visualizations (e.g., genomic and flow data modules), shareable dashboards, internal and external notifications, and application programming interfaces (APIs)/connectors that allow the QuartzBio solutions to empower decision making in the context of a complex data ecosystem.
“We’re very excited to join Precision for Medicine and become a part of QuartzBio,” says Mark Kaganovich, SolveBio’s Co-Founder and CEO. “It’s a big opportunity to continue improving our offering to our customers.” “QuartzBio’s acquisition of SolveBio is a major step forward in our goal to solve biomarker data management for the pharmaceutical and biotech industry,” says David Caplan, SolveBio’s Co-Founder and CTO. “By joining QuartzBio’s amazing team, we will be able to provide the comprehensive solution our clients need to get precision treatments out to patients faster. We are honored to be a part of this journey.”
About Precision for Medicine
Precision for Medicine is the first biomarker-driven clinical research services organization supporting life sciences companies in the use of biomarkers essential to targeting patient treatments more precisely and effectively. Precision applies novel biomarker approaches to clinical research that integrate clinical trial design and execution with deep scientific knowledge, laboratory expertise and advanced data sciences. This convergence of trials, labs and data sciences is driving faster clinical development and approval. Precision for Medicine is part of Precision Medicine Group, with 3,200 people in 40 locations in the U.S., Canada, Europe and Australia. For more information, visit PrecisionForMedicine.com.
About QuartzBio
QuartzBio helps overcome the data chaos inherent in modern drug development. We serve clinical operations and translational research teams in oncology, autoimmune, CNS and other biomarker-rich therapeutic areas, whose progress hinges on navigating and connecting a complex data ecosystem. Our suite of fully connected, end-to-end SaaS solutions is engineered specifically to address the challenges of both sample data and biomarker data management – providing a single, scalable data platform solution to the biotech and pharma sectors. For more information, visit Quartzbio.com.
About SolveBio
SolveBio is an industry leader in advanced precision medicine data analytics. Its technology platform enables biopharma customers to lower trial risk, create more effective therapeutics, and compress the time scale of clinical development. The core of SolveBio’s platform is technology to connect genomic data that comes from a rapidly compounding complex landscape of vendors, studies, and patients.
Media Contact
Ann Smith Precision Medicine Group Media Relations 201-680-9447 asmith@coynepr.com
https://www.quartz.bio/wp-content/uploads/2023/01/QuartzBio-SolveBio-PR-Social-Image-20230123-1.png12001200Michael Rubinhttps://www.quartz.bio/wp-content/uploads/2022/03/logo.svgMichael Rubin2023-01-24 08:55:002023-01-23 21:46:42QuartzBio, a Part of Precision for Medicine, Acquires SolveBio and Expands Software-as-a-Service (SaaS) Data Management Solutions for Clinical Research & Development